 Namila Bandara
Namila BandaraA Simple Redis Cluster on Windows

Recently I’ve worked on a project where we enabled Redis caching for our web applications. So for that, I had a chance to develop a custom reactive spring-boot Redis cluster client library (for a Spring webflux project) and integrate it. The problem I faced was the AWS Redis cluster nodes were not available for my office VPN (maybe ssh-ing to the bastion server and trying to connect Redis will work, I haven’t tried it). When testing the new service on the local set was a nightmare as I don’t have the Docker desktop(due to the subscription).
Hence I tried to create a small Redis cluster on windows as I can use this for my local dev testing with the Redis client library (currently, I’m developing on the windows platform). In this article, I will give an introduction to Redis, its topologies, its clustering configurations and some database theories(just for fun 😁 ). You can skip straight to the Lets build a Redis cluster.
Some Database Theories First
Let’s talk about some Database theories. Here I’ll be going to discuss database types, Data fragmentation and replication. So What is a database? according to the definition; “Database is a collection of organized data which is structured and stored electronically on a computer system”. DBMS is used to store a huge amount of data and enables to search and locate the data immediately. Database types can be categorized based on model, locations, processing powers and hostings.
Database types based on model
When talking about db types based on model, there are three types; Relational, No-Sql(Non relational) and object.
1. Relational Database
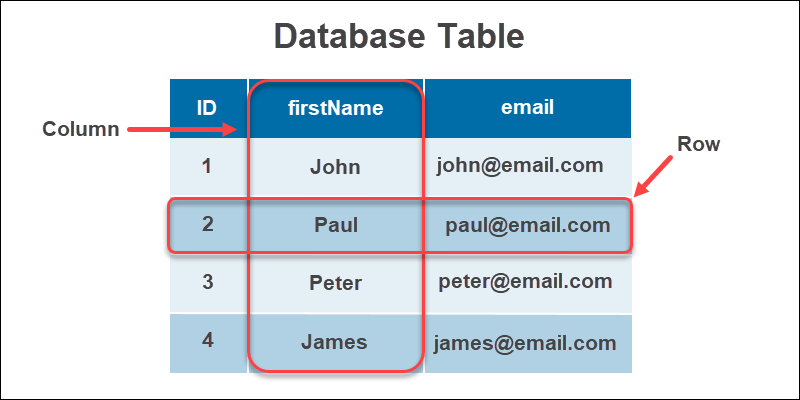
This is the most oldest and used DB type. Here data is stored in tables as rows and values as an attribute in columns. The SQL language is used to query the data. These DBs are stable and support a range of data types and are ACID compliant. These are mainly used in online transactions, data warehouses. OracleDB, MySQL,Postgres are some popular relational databases.
2. Non-Relational Database (NoSQL)
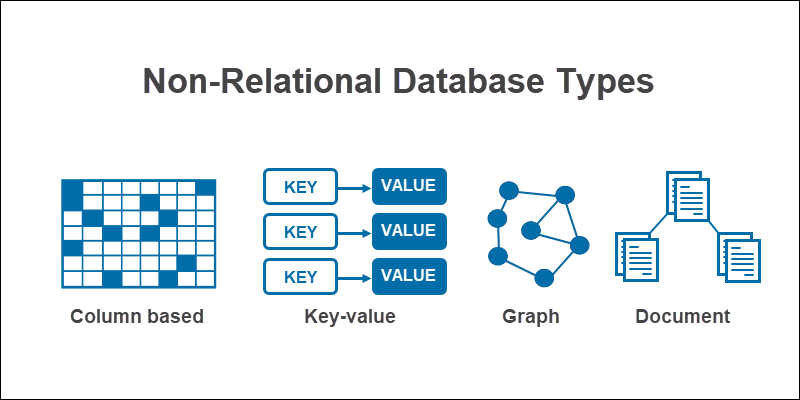
In non-relational DBs, there are no tables. Data can be stored in flexible data models. Commonly used No-SQL databases are; Documented databases, Key-value stores, wide-column based DBs and graphs DBs. The main features are; support for multiple data structures, flexibility due to non/semi-structured data and scalability. Those types of DBs are mainly used in Real-time systems. Popular NoSQL DBs are; MongoDB, Redis, CouchDB.
Database types based on location
There are different types of database based on physical locations;
1. Centralised Database
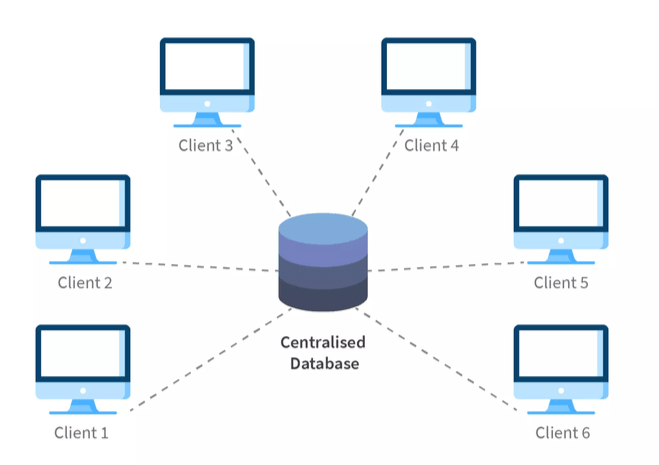
All data and information are stored in a single location where it can be accessed from numerous locations. The main features are; Data integrity as data is in single location and reduces redundancy, simplicity and cost-effectiveness. Those are mainly used in onsite school and universities, government organizations etc.
2. Distributed Database
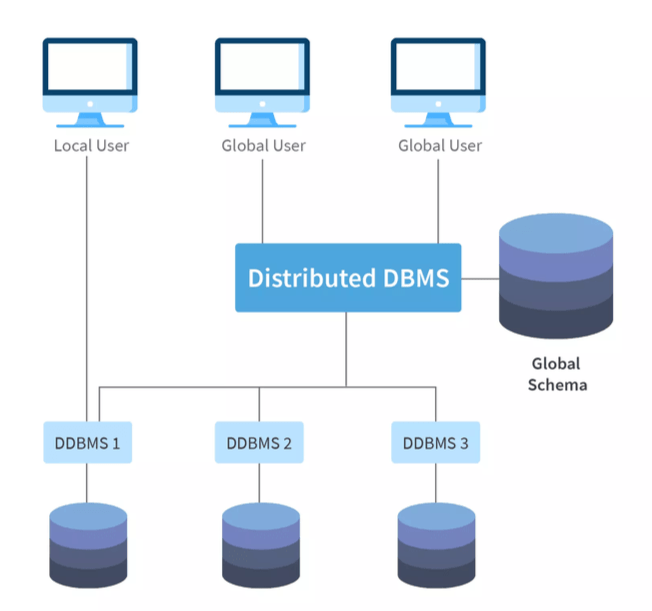
A distributed database is multiple interconnected DBs spread out in different locations connected by a network. As the DBs are all connected end users see them as a single DB. These can scale horizontally by adding multiple nodes which offer greater availability. A centralized distributed database management system (DDBMS) manages all the data as its in one place and allows to synchronize of all data operations among the DBs. The main features are; location isolation, distributed query processing and transaction management.
There are mainly two type of distributed database types;
- Homogeneous DDBS - A network of identical databases stored in multiple locations where all share the same OS and DB schemas. These systems are easy to manage and design.
- Heterogeneous DDBS - This results when different individual systems have implemented their own DBs to integrate later. They uses different schemas, DDBMs. A communication translation is required to establish communication between different DBMSs.
Database Partitioning (Sharding)
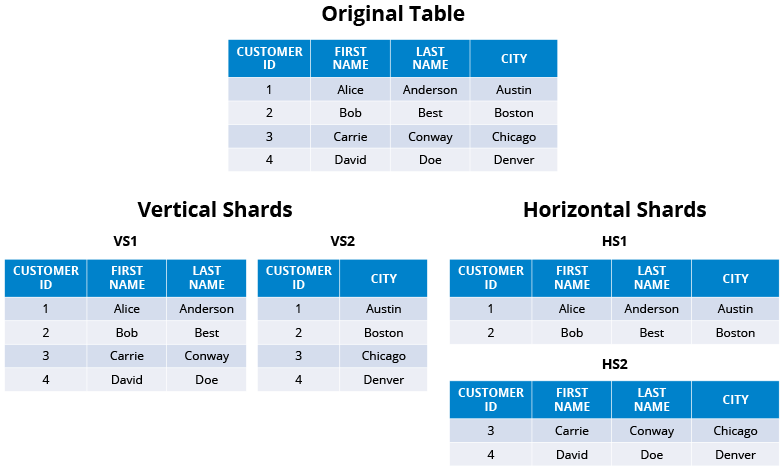
- Vertical Partitioning
- This is mainly used in SQL DBs to increase performances when a query is retrieving all columns from a table that contains many lengthy text or BLOBs. To reduce the access time, it can be splitted into smaller tables containing a partition key and the huge BLOB/text.
- Horizontal Partitioning
- This is replicating the schema of the original table and then dividing the data based on a partition key into separated tables/ DBMS nodes which will spread the load to the original server. It can be split based on a range, hashing function etc.
So whats the difference between Sharding and Partitioning?
Partitioning is a generic term used to define the split large data in to smaller chuncks based on different physical entities for the performance. The difference is that sharding (type of horizontal partitioning) implies that data is spread across different DBMS systems and regions while partitioning is all spliting data in same DBMS.
What is Redis?
Redis (REmote DIctionary Server) is an opensource in-memory key-value data store written in C, where it can be used as a database,cache,message broker. These are the main data types available on Redis1;
- Strings - Binary safe, basic data type in Redis. Can store upto 512Mb in one string.
- Lists - list of strings, sorted by insertion order. Can push elements to head or tail.
- Sets - unordered collection of strings. Can compute union,intersection etc. in very short period
- Hashes - Map with string key and value. Best for represet objects.
- Streams - Data sturcutre like appends only logs. useuflu for record streaming events in order.
In default, Redis persist data on the memory. But it has two type of disk persistence options;
- RDB (Redis Database) - creates point-in-time snapshot of your data set at specific intervals
- AOF (Append Only File) - writes every write operations received by the server. On startup thiw will be played to reconstruct the original database
Types of Redis Topologies
There are mainly four types of Redis topologies. Standalone,Replicate,Sentinel and Cluster.
1. Redis Standalone
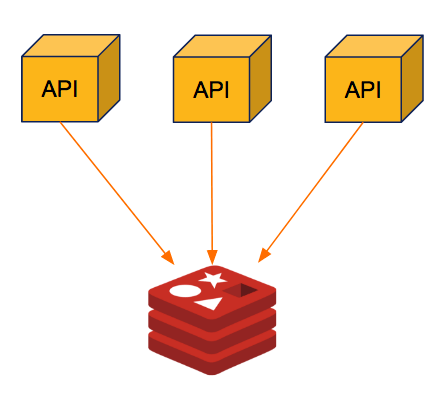
Pros:
- Easy to deploy
Cons:
- Can scale vertically by using bigger hardwares
2. Redis Replicated
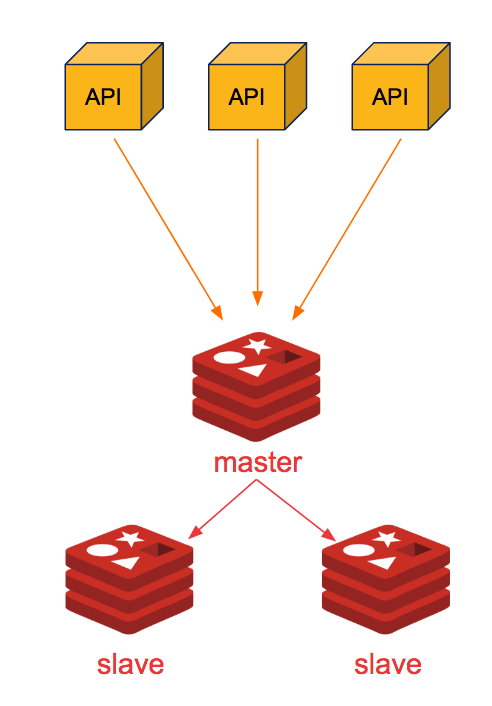
- Easy to setup
- Data safety,there’s always a backup of your data
- Read scalibility as its distributed.
Cons:
- Writing operations are done only by the master node
- Need manual operations once the master is down (changing master node or restarting it)
- Not guarantee the data consistency
3. Redis Sentinel
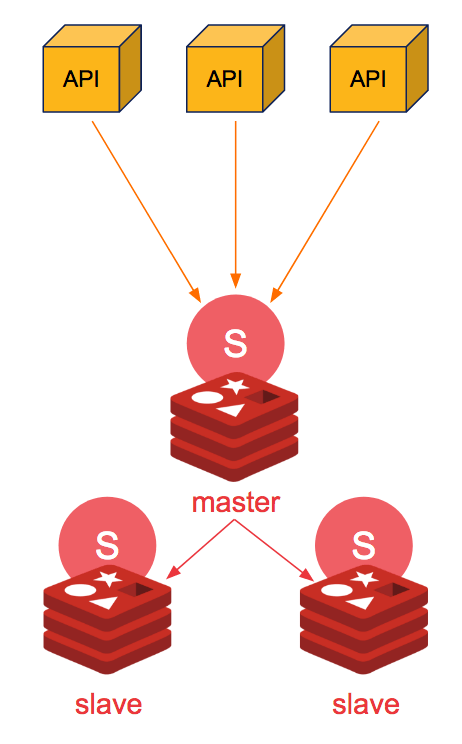
Pros:
- High Availability and automatic resilience
- Built in Redis and easy to setup
- Service discovery and aware of current Redis topology
Cons:
- Need to handle nodes seperately
- Not scalable as all the writes are going to the master node
- Not guarantee the data consistency as the replications is done in asynchronous
- Clients needs to support Redis sentinel.
4. Redis Cluster
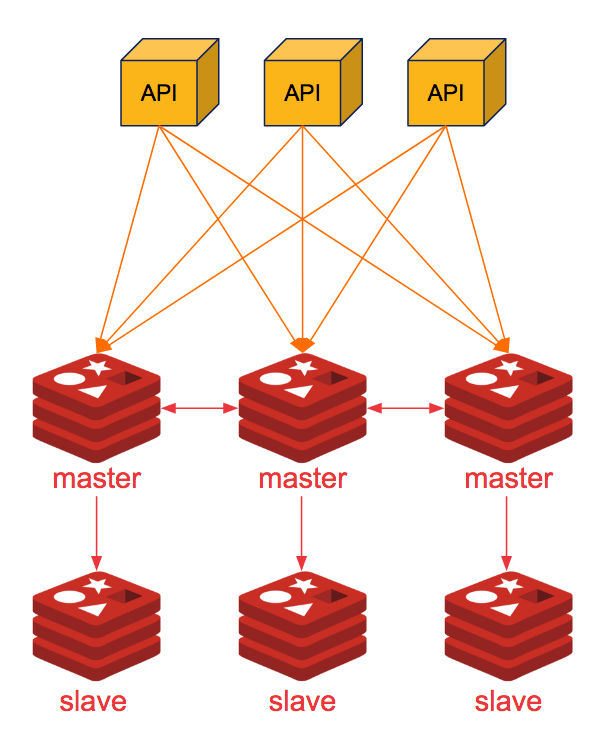
Pros:
- High Availability and scalibility
- Decentralized architecture, data are distributed among the nodes
- Automatic failuer recovery
Cons:
- Need minimum of 6 nodes to setup
- Clients should be aware of the Redis cluster
- Data is replicated asynchronusly
Bit about Redis Clustering
Redis cluster is providing an automatic way to share the data across multiple Redis nodes. This provides “some degree” of availability during failuers4. Redis cluster uses a form of sharding where every key is a part of a hash slot5. There are 16384 hash slots available in the Redis cluster and when computing the slot Redis uses CRC16 of key modulo 16384.
HASH_SLOT = CRC16(key) mod 16384
Using hash slots, users able to add/remove new master slots to the cluster, all you have to do is move some hash key slots from the 3 master node to new master node with zero down time. Mean time what will happen if one of the master node fails? Lets say Master 2 Node got crashed or instance got stopped. We will loose hash keys 5462-10923 and the data stored in the keys. To over come this issue we uses Redis cluster master-replica model.
In our example we have created 3 masters and 3 slaves which acts as a replica for each master nodes. Ideally these master nodes and its replica are grouped in different instances. for example; we create a instance for Master node 1 with Slave(3), Master(2) with Slave(1 ) and Master(3) with slave(2). If Master(2) failed, its replica, slave(2) node will promoted as the new master(2) and continue to work. But however if both Master(2) and Slave(2) got failed at same time, the cluster will loose all the keys.
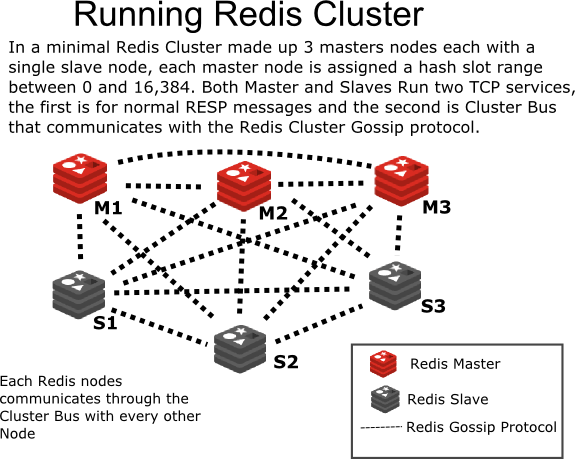
intro2libsys.com)When Redis is in cluster mode each node has two TCP sockets running; the first is a standard Redis protocol for client connection (default 6379) and the second TCP port first Port+10000 (default 16379) is for cluster bus, node-to-node communication.
To create a cluster, we need a few instances of Redis which are running in cluster mode. To setup it, these are the minimum configurations
|
|
Setting the cluster-enabled to yes, enables the Redis clustering mode. Each cluster node generates a cluster-config-file` to keep node-related data.
For minimal cluster configurations, there should be at least 3 master nodes
Lets Build A Cluster
In this tutorial, we are going to create a 6-node Redis cluster with 3 masters and 3 slave nodes and assign 3 separate slot ranges for each master as shown in the figure.
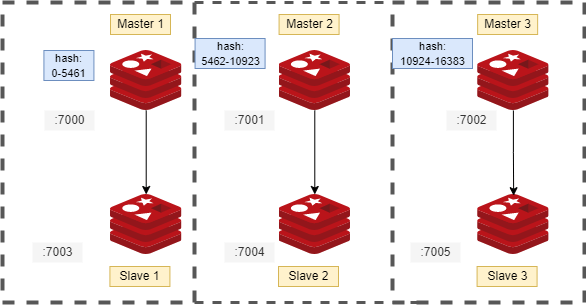
- Master Node 1 (M1) - allocated hash slots 0-5460
- Master Node 2 (M2) - allocated hash slots 5461-10922
- Master Node 3 (M3) - allocated hash slots 10923-16383
- Slave Node 1(S1) - replicates M1
- Slave Node 2(S2) - replicates M2
- Slave Node 3(S3) - replicates M3
-
First get the latest Redis for the windows zip from here
-
Create 6 seperate folders for each nodes (M1…S3) and paste the Redis binaries.
-
Update and uncomment the following fields in
Redis.windows.conffor each folder; Change the port for each master and slave. M1-7000,M2-7001,M3-7002,S1-7003,S2-7004,S5-7006. (sample config)1 2 3 4 5 6port 7000 #change this on each nodes cluster-enabled yes # uncomment the following cluster-config-file nodes.conf cluster-node-timeout 5000 appendonly yes -
Now open the
CMDfor each folder location andRedis-server.exe Redis.windows.confto start the Redis servers. For this I have created a small script which enables to run all the Redis servers at once in a minimized cmd. copy this to the root folder (where all the node folders contains) and execute. -
Now we have 6 running Redis instances. All we need is to initiating the cluster. For that you can run the following command;
In here we’re using1 2Redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1--cluster-replicas 1which means for every master created, Redis will create a replica.Redis-cliwill show the current setup and you can typeYESto proceed and create the cluser. If everything goes correctly you will recieve this message,
[OK] All 16384 slots covered
.The script will looks like this
If you want to create a cluster with a defined master and slaves node, you have to define which will be master nodes and which will be the slaves, so for that, you have to run the command with master IP addresses with --cluster-replicas 0. Then you need to take the node ids of the master and assign slaves for each master node. To retrieve the master node’s node-id, use Redis-cli -c -h 127.0.0.1 -p <PORT> cluster nodes and get the node name with myself,master tag. Then assign the slave for the master nod id as;
|
|
-
To connect with a master server, you need to use Redis-cli with the
-cto support the redirections between cluster nodes.1 2Redis-cli -c -h 127.0.0.1 -p 7000 -
Finally you need a script to kill all running Redis-server processes.
So that’s all for this article. See you soon!!!👋
References and Read More
- data-types - redis.io
- persistence - redis.io
- Parallel and distributed databases
- FUNDAMENTALS OF Database Systems PDF - chapter 2.5
- DBMS Tutorial
- Database Types Explained - phoenixnap.com
- What Is a Distributed Database? - phoenixnap.com
- Distributed Database Concepts - oracle.com
- What Redis deployment do you need - octo.com
- What Is Sharding? - hazelcast.com
- Database Sharding vs. Partitioning: What’s the Difference? - singlestore.com